本文最后更新于:January 9, 2023 pm
本文主要在centos7系统上基于containerd和v3.24.5版本的calico组件部署v1.26.0版本的堆叠ETCD高可用k8s原生集群,在LoadBalancer上选择了PureLB和calico结合bird实现BGP路由可达 的K8S集群部署。
此前写的一些关于k8s基础知识和集群搭建的一些方案 ,有需要的同学可以看一下。
1、准备工作 1.1 集群信息 机器均为16C16G的虚拟机,硬盘为100G。
IP
Hostname
10.31.90.0
k8s-calico-apiserver.tinychen.io
10.31.90.1
k8s-calico-master-10-31-90-1.tinychen.io
10.31.90.2
k8s-calico-master-10-31-90-2.tinychen.io
10.31.90.3
k8s-calico-master-10-31-90-3.tinychen.io
10.31.90.4
k8s-calico-worker-10-31-90-4.tinychen.io
10.31.90.5
k8s-calico-worker-10-31-90-5.tinychen.io
10.31.90.6
k8s-calico-worker-10-31-90-6.tinychen.io
10.33.0.0/17
podSubnet
10.33.128.0/18
serviceSubnet
10.33.192.0/18
LoadBalancerSubnet
1.2 检查mac和product_uuid 同一个k8s集群内的所有节点需要确保mac地址和product_uuid均唯一,开始集群初始化之前需要检查相关信息
link cat /sys/class/dmi/id/product_uuid
1.3 配置ssh免密登录(可选) 如果k8s集群的节点有多个网卡,确保每个节点能通过正确的网卡互联访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 cd /root/.ssh/cat id_rsa.pub >> authorized_keyschmod 600 authorized_keyscat >> ~/.ssh/config <<EOF Host k8s-calico-master-10-31-90-1 HostName 10.31.90.1 User root Port 22 IdentityFile ~/.ssh/id_rsa Host k8s-calico-master-10-31-90-2 HostName 10.31.90.2 User root Port 22 IdentityFile ~/.ssh/id_rsa Host k8s-calico-master-10-31-90-3 HostName 10.31.90.3 User root Port 22 IdentityFile ~/.ssh/id_rsa Host k8s-calico-worker-10-31-90-4 HostName 10.31.90.4 User root Port 22 IdentityFile ~/.ssh/id_rsa Host k8s-calico-worker-10-31-90-5 HostName 10.31.90.5 User root Port 22 IdentityFile ~/.ssh/id_rsa Host k8s-calico-worker-10-31-90-6 HostName 10.31.90.6 User root Port 22 IdentityFile ~/.ssh/id_rsa EOF
1.4 修改hosts文件 cat >> /etc/hosts <<EOF 10.31.90.0 k8s-calico-apiserver k8s-calico-apiserver.tinychen.io 10.31.90.1 k8s-calico-master-10-31-90-1 k8s-calico-master-10-31-90-1.tinychen.io 10.31.90.2 k8s-calico-master-10-31-90-2 k8s-calico-master-10-31-90-2.tinychen.io 10.31.90.3 k8s-calico-master-10-31-90-3 k8s-calico-master-10-31-90-3.tinychen.io 10.31.90.4 k8s-calico-worker-10-31-90-4 k8s-calico-worker-10-31-90-4.tinychen.io 10.31.90.5 k8s-calico-worker-10-31-90-5 k8s-calico-worker-10-31-90-5.tinychen.io 10.31.90.6 k8s-calico-worker-10-31-90-6 k8s-calico-worker-10-31-90-6.tinychen.io EOF
1.5 关闭swap内存 '/swap / s/^\(.*\)$/#\1/g' /etc/fstab
1.6 配置时间同步 这里可以根据自己的习惯选择ntp或者是chrony同步均可,同步的时间源服务器可以选择阿里云的ntp1.aliyun.com或者是国家时间中心的ntp.ntsc.ac.cn。
使用ntp同步
使用chrony同步 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 enable chronyd.service
1.7 关闭selinux 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
1.8 配置防火墙 k8s集群之间通信和服务暴露需要使用较多端口,为了方便,直接禁用防火墙
disable firewalld.service
1.9 配置netfilter参数 这里主要是需要配置内核加载br_netfilter和iptables放行ipv6和ipv4的流量,确保集群内的容器能够正常通信。
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF
1.10 配置IPVS IPVS是专门设计用来应对负载均衡场景的组件,kube-proxy 中的 IPVS 实现 通过减少对 iptables 的使用来增加可扩展性。在 iptables 输入链中不使用 PREROUTING,而是创建一个假的接口,叫做 kube-ipvs0,当k8s集群中的负载均衡配置变多的时候,IPVS能实现比iptables更高效的转发性能。
注意在4.19之后的内核版本中使用nf_conntrack模块来替换了原有的nf_conntrack_ipv4模块
(Notes : use nf_conntrack instead of nf_conntrack_ipv4 for Linux kernel 4.19 and later)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cat <<EOF | sudo tee /etc/modules-load.d/ipvs.conf ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack EOF cut -f1 -d " " /proc/modules | grep -e ip_vs -e nf_conntrack
2、安装container runtime 2.1 安装containerd 详细的官方文档可以参考这里 ,由于在刚发布的1.24版本中移除了docker-shim,因此安装的版本≥1.24的时候需要注意容器运行时的选择。这里我们安装的版本为最新的1.26,因此我们不能继续使用docker,这里我们将其换为containerd
修改Linux内核参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf overlay br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 EOF
安装containerd centos7比较方便的部署方式是利用已有的yum源进行安装,这里我们可以使用docker官方的yum源来安装containerd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sort -renable --now containerd
关于CRI 官方表示,对于k8s来说,不需要安装cri-containerd,并且该功能会在后面的2.0版本中废弃。
FAQ : For Kubernetes, do I need to download cri-containerd-(cni-)<VERSION>-<OS-<ARCH>.tar.gz too?
Answer : No.
As the Kubernetes CRI feature has been already included in containerd-<VERSION>-<OS>-<ARCH>.tar.gz, you do not need to download the cri-containerd-.... archives to use CRI.
The cri-containerd-... archives are deprecated , do not work on old Linux distributions, and will be removed in containerd 2.0.
安装cni-plugins 使用yum源安装的方式会把runc安装好,但是并不会安装cni-plugins,因此这部分还是需要我们自行安装。
The containerd.io package contains runc too, but does not contain CNI plugins.
我们直接在github上面 找到系统对应的架构版本,这里为amd64,然后解压即可。
sha512sum -c cni-plugins-linux-amd64-v1.1.1.tgz.sha512mkdir -p /opt/cni/bin
2.2 配置cgroup drivers CentOS7使用的是systemd来初始化系统并管理进程,初始化进程会生成并使用一个 root 控制组 (cgroup), 并充当 cgroup 管理器。 Systemd 与 cgroup 集成紧密,并将为每个 systemd 单元分配一个 cgroup。 我们也可以配置容器运行时和 kubelet 使用 cgroupfs。 连同 systemd 一起使用 cgroupfs 意味着将有两个不同的 cgroup 管理器。而当一个系统中同时存在cgroupfs和systemd两者时,容易变得不稳定,因此最好更改设置,令容器运行时和 kubelet 使用 systemd 作为 cgroup 驱动,以此使系统更为稳定。 对于containerd, 需要设置配置文件/etc/containerd/config.toml中的 SystemdCgroup 参数。
参考k8s官方的说明文档:
https://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd-systemd
[plugins."io.containerd.grpc.v1.cri" .containerd.runtimes.runc]"io.containerd.grpc.v1.cri" .containerd.runtimes.runc.options]true
接下来我们开始配置containerd的cgroup driver
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 false cat /etc/containerd/config.toml | egrep -v "^#|^$" "cri" ]mv /etc/containerd/config.toml /etc/containerd/config.toml.origin's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.tomltrue "2022-05-12T09:57:31.100285056+08:00" level=error msg="failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni config load failed: no network config found in /etc/cni/net.d: cni plugin not initialized: failed to load cni config"
2.3 关于kubelet的cgroup driver k8s官方有详细的文档 介绍了如何设置kubelet的cgroup driver,需要特别注意的是,在1.22版本开始,如果没有手动设置kubelet的cgroup driver,那么默认会设置为systemd
Note: In v1.22, if the user is not setting the cgroupDriver field under KubeletConfiguration, kubeadm will default it to systemd.
一个比较简单的指定kubelet的cgroup driver的方法就是在kubeadm-config.yaml加入cgroupDriver字段
kind: ClusterConfiguration apiVersion: kubeadm.k8s.io/v1beta3 kubernetesVersion: v1.21.0 --- kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd
我们可以直接查看configmaps来查看初始化之后集群的kubeadm-config配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 $ kubectl describe configmaps kubeadm-config -n kube-systemData ==== ClusterConfiguration: ---- extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s local: dataDir: /var/lib/etcd dnsDomain: cali-cluster.tclocal serviceSubnet: 10.88.0.0/18 BinaryData ====
当然因为我们需要安装的版本高于1.22.0并且使用的就是systemd,因此可以不用再重复配置。
3、安装kube三件套
对应的官方文档可以参考这里
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#installing-kubeadm-kubelet-and-kubectl
kube三件套就是kubeadm、kubelet 和 kubectl,三者的具体功能和作用如下:
kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动 Pod 和容器等。kubectl:用来与集群通信的命令行工具。
需要注意的是:
kubeadm不会帮助我们管理kubelet和kubectl,其他两者也是一样的,也就是说这三者是相互独立的,并不存在谁管理谁的情况;kubelet的版本必须小于等于API-server的版本,否则容易出现兼容性的问题;kubectl并不是集群中的每个节点都需要安装,也并不是一定要安装在集群中的节点,可以单独安装在自己本地的机器环境上面,然后配合kubeconfig文件即可使用kubectl命令来远程管理对应的k8s集群;
CentOS7的安装比较简单,我们直接使用官方提供的yum源即可。需要注意的是这里需要设置selinux的状态,但是前面我们已经关闭了selinux,因此这里略过这步。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg exclude=kubelet kubeadm kubectl EOF cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF 's/repo_gpgcheck=1/repo_gpgcheck=0/g' /etc/yum.repos.d/kubernetes.repoenable --now kubelet
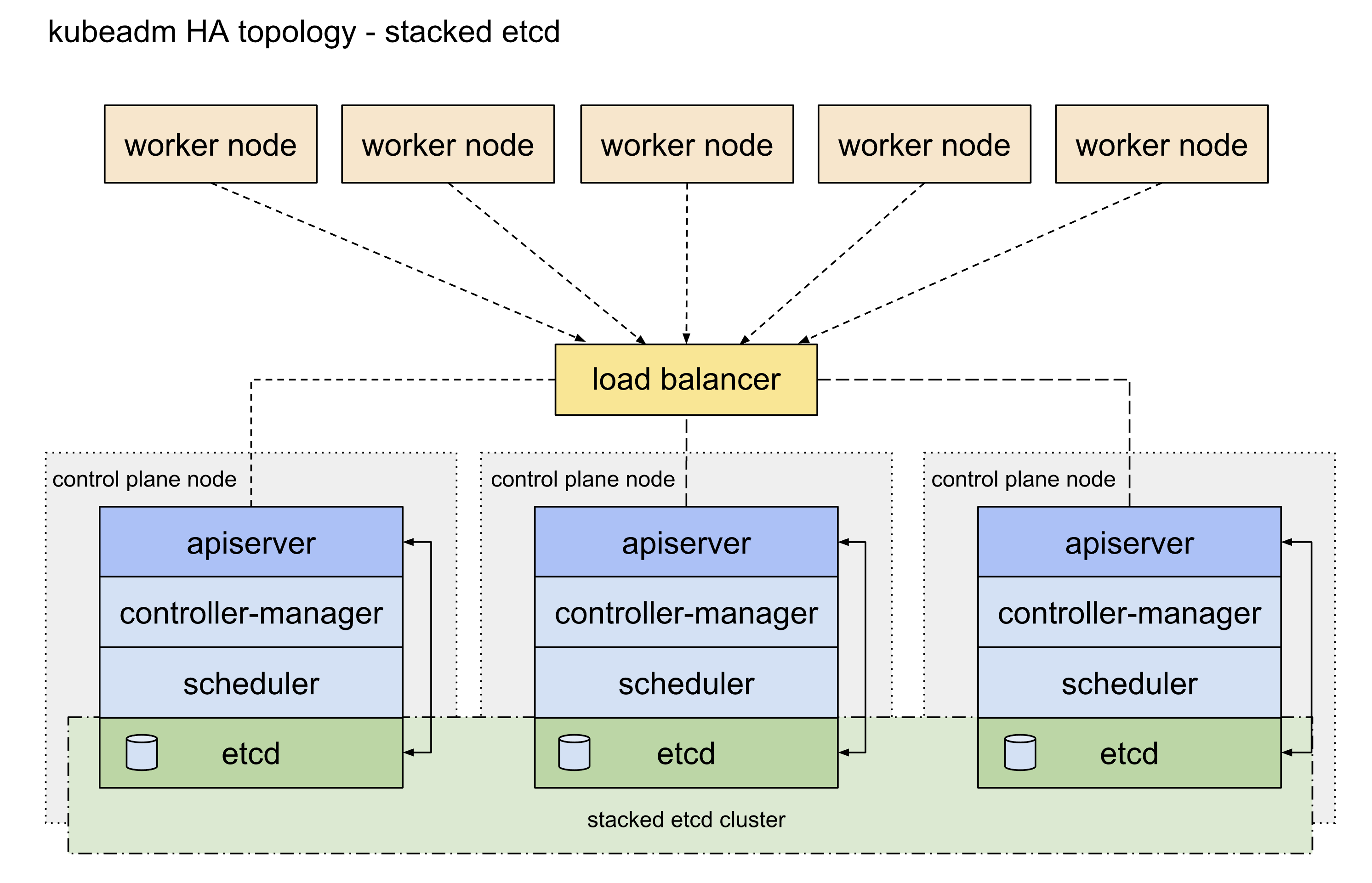
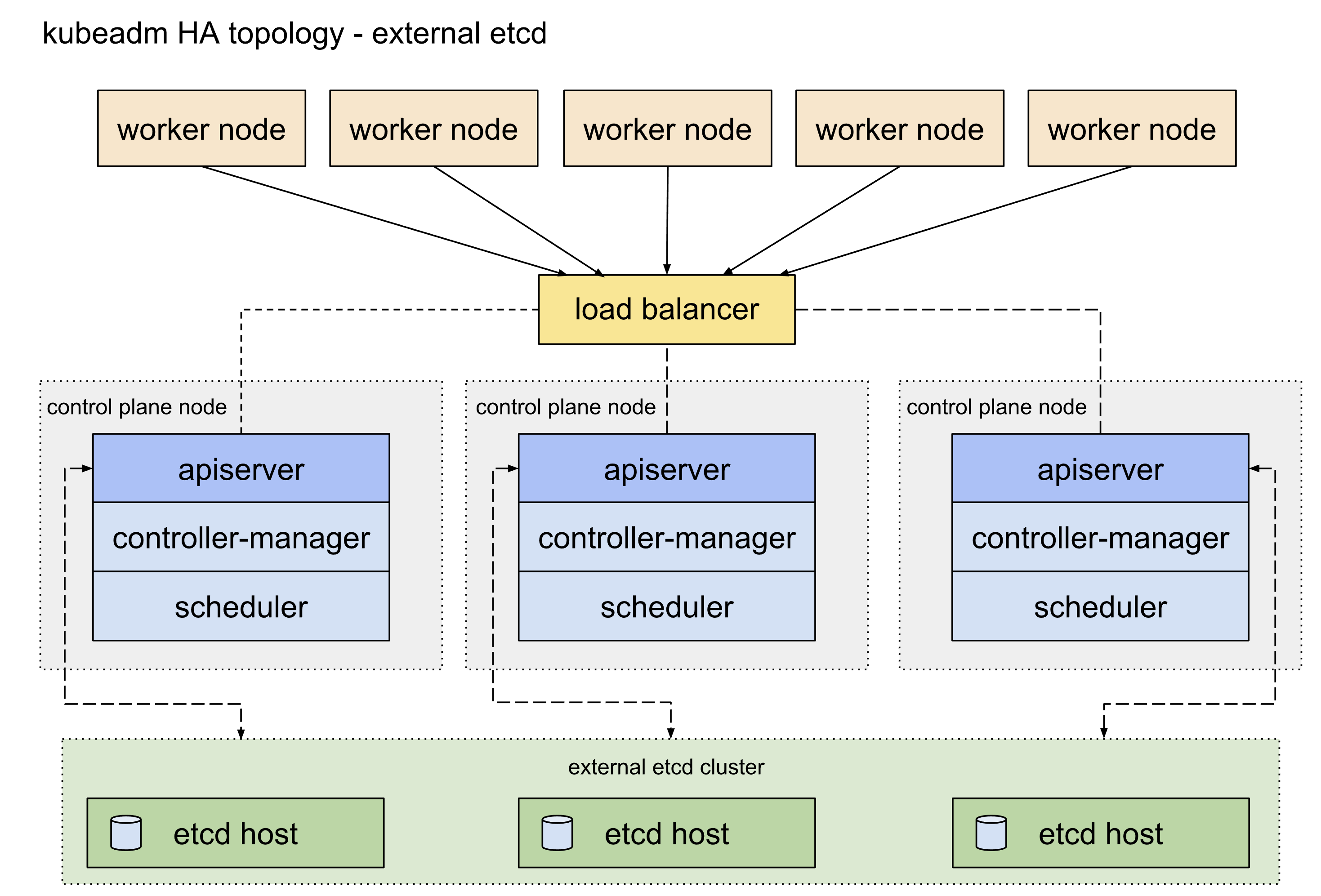
4、初始化集群 4.0 etcd高可用 etcd高可用架构参考这篇官方文档 ,主要可以分为堆叠etcd方案和外置etcd方案,两者的区别就是etcd是否部署在apiserver所在的node机器上面,这里我们主要使用的是堆叠etcd部署方案。
4.1 apiserver高可用 apisever高可用配置参考这篇官方文档 。目前apiserver的高可用比较主流的官方推荐方案 是使用keepalived和haproxy,由于centos7自带的版本较旧,重新编译又过于麻烦,因此我们可以参考官方给出的静态pod的部署方式 ,提前将相关的配置文件放置到/etc/kubernetes/manifests目录下即可(需要提前手动创建好目录)。官方表示对于我们这种堆叠部署控制面master节点和etcd的方式而言这是一种优雅的解决方案。
This is an elegant solution, in particular with the setup described under Stacked control plane and etcd nodes .
首先我们需要准备好三台master节点上面的keepalived配置文件和haproxy配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ! /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id LVS_DEVEL } vrrp_script check_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI_1 { state ${STATE} interface $ {INTERFACE} virtual_router_id $ {ROUTER_ID} priority $ {PRIORITY} authentication { auth_type PASS auth_pass ${AUTH_PASS} } virtual_ipaddress { ${APISERVER_VIP} } track_script { check_apiserver } }
实际上我们需要区分三台控制面节点的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ! /etc/keepalived/keepalived.conffor keepalived"/etc/keepalived/check_apiserver.sh" int erval 3 -2 10 2 interface eth0 virtual_router_id 90 priority 100 authentication {pass@ 77 10.31 .90 .0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ! /etc/keepalived/keepalived.conffor keepalived"/etc/keepalived/check_apiserver.sh" int erval 3 -2 10 2 interface eth0 virtual_router_id 90 priority 99 authentication {pass@ 77 10.31 .90 .0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ! /etc/keepalived/keepalived.conffor keepalived"/etc/keepalived/check_apiserver.sh" int erval 3 -2 10 2 interface eth0 virtual_router_id 90 priority 98 authentication {pass@ 77 10.31 .90 .0
这是haproxy的配置文件模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 log /dev/log local0log /dev/log local1 noticelog globaltimeout http-request 10stimeout queue 20stimeout connect 5stimeout client 20stimeout server 20stimeout http-keep-alive 10stimeout check 10sbind *:${APISERVER_DEST_PORT} ${HOST1_ID} ${HOST1_ADDRESS} :${APISERVER_SRC_PORT} check
这是keepalived的检测脚本,注意这里的${APISERVER_VIP}和${APISERVER_DEST_PORT}要替换为集群的实际VIP和端口
# !/bin/sh
这是keepalived的部署文件/etc/kubernetes/manifests/keepalived.yaml,注意这里的配置文件路径要和上面的对应一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: v1 kind: Pod metadata: creationTimestamp: null name: keepalived namespace: kube-system spec: containers: - image: osixia/keepalived:2.0.17 name: keepalived resources: {}securityContext: capabilities: add: - NET_ADMIN - NET_BROADCAST - NET_RAW volumeMounts: - mountPath: /usr/local/etc/keepalived/keepalived.conf name: config - mountPath: /etc/keepalived/check_apiserver.sh name: check hostNetwork: true volumes: - hostPath: path: /etc/keepalived/keepalived.conf name: config - hostPath: path: /etc/keepalived/check_apiserver.sh name: check status: {}
这是haproxy的部署文件/etc/kubernetes/manifests/haproxy.yaml,注意这里的配置文件路径要和上面的对应一致,且${APISERVER_DEST_PORT}要换成我们对应的apiserver的端口,这里我们改为8443,避免和原有的6443端口冲突
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiVersion: v1 kind: Pod metadata: name: haproxy namespace: kube-system spec: containers: - image: haproxy:2.1.4 name: haproxy livenessProbe: failureThreshold: 8 httpGet: host: localhost path: /healthz port: 8443 scheme: HTTPS volumeMounts: - mountPath: /usr/local/etc/haproxy/haproxy.cfg name: haproxyconf readOnly: true hostNetwork: true volumes: - hostPath: path: /etc/haproxy/haproxy.cfg type: FileOrCreate name: haproxyconf status: {}
4.2 编写配置文件 在集群中所有节点都执行完上面的操作之后,我们就可以开始创建k8s集群了。因为我们这次需要进行高可用部署,所以初始化的时候先挑任意一台master控制面节点进行操作即可。
print init-defaults > kubeadm-calico-ha.conf
考虑到大多数情况下国内的网络无法使用谷歌的镜像源(1.25版本开始从k8s.gcr.io换为registry.k8s.io),我们可以直接在配置文件中修改imageRepository参数为阿里的镜像源registry.aliyuncs.com/google_containers
kubernetesVersion字段用来指定我们要安装的k8s版本localAPIEndpoint参数需要修改为我们的master节点的IP和端口,初始化之后的k8s集群的apiserver地址就是这个criSocket从1.24.0版本开始已经默认变成了containerdpodSubnet、serviceSubnet和dnsDomain两个参数默认情况下可以不用修改,这里我按照自己的需求进行了变更nodeRegistration里面的name参数修改为对应master节点的hostnamecontrolPlaneEndpoint参数配置的才是我们前面配置的集群高可用apiserver的地址新增配置块使用ipvs,具体可以参考官方文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 10.31 .90 .1 bindPort: 6443 nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: k8s-calico-master-10-31-90-1.tinychen.io taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {}dns: {}etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: 1.26 .0 controlPlaneEndpoint: "k8s-calico-apiserver.tinychen.io:8443" networking: dnsDomain: cali-cluster.tclocal serviceSubnet: 10.33 .128 .0 /18 podSubnet: 10.33 .0 .0 /17 scheduler: {}--- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs
4.3 初始化集群 此时我们再查看对应的配置文件中的镜像版本,就会发现已经变成了对应阿里云镜像源的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 for setting up a Kubernetes clusterin beforehand using 'kubeadm config images pull'
当我们看到下面这个输出结果的时候,我们的集群就算是初始化成功了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Your Kubernetes control-plane has initialized successfully!mkdir -p $HOME /.kubecp -i /etc/kubernetes/admin.conf $HOME /.kube/configchown $(id -u):$(id -g) $HOME /.kube/configif you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.conf"kubectl apply -f [podnetwork].yaml" with one of the options listed at:join any number of the control-plane node running the following command on each as root:join k8s-calico-apiserver.tinychen.io:8443 --token abcdef.0123456789abcdef \in two hours; If necessary, you can use"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.join any number of worker nodes by running the following on each as root:join k8s-calico-apiserver.tinychen.io:8443 --token abcdef.0123456789abcdef \
接下来我们在剩下的两个master节点上面执行上面输出的命令,注意要执行带有--control-plane --certificate-key这两个参数的命令,其中--control-plane参数是确定该节点为master控制面节点,而--certificate-key参数则是把我们前面初始化集群的时候通过--upload-certs上传到k8s集群中的证书下载下来使用。
This node has joined the cluster and a new control plane instance was created:to apiserver and approval was received.of the new secure connection details.and taint were applied to the new node.new etcd member was added to the local /stacked etcd cluster.start administering your cluster from this node, you need to run the following as a regular user:'kubectl get nodes' to see this node join the cluster.
最后再对剩下的三个worker节点执行普通的加入集群命令,当看到下面的输出的时候说明节点成功加入集群了。
This node has joined the cluster:'kubectl get nodes' on the control-plane to see this node join the cluster.
如果不小心没保存初始化成功的输出信息,或者是以后还需要新增节点也没有关系,我们可以使用kubectl工具查看或者生成token
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 查看现有的token列表 $ kubeadm token list # 如果token已经失效,那就再创建一个新的token $ kubeadm token create $ kubeadm token list # 如果找不到--discovery-token-ca-cert-hash参数,则可以在master节点上使用openssl工具来获取 $ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
4.4 配置kubeconfig 刚初始化成功之后,我们还没办法马上查看k8s集群信息,需要配置kubeconfig相关参数才能正常使用kubectl连接apiserver读取集群信息。
mkdir -p $HOME /.kubecp -i /etc/kubernetes/admin.conf $HOME /.kube/configchown $(id -u):$(id -g) $HOME /.kube/configexport KUBECONFIG=/etc/kubernetes/admin.confecho "source <(kubectl completion bash)" >> ~/.bashrc
前面我们提到过kubectl不一定要安装在集群内,实际上只要是任何一台能连接到apiserver的机器上面都可以安装kubectl并且根据步骤配置kubeconfig,就可以使用kubectl命令行来管理对应的k8s集群。
配置完成后,我们再执行相关命令就可以查看集群的信息了,但是此时节点的状态还是NotReady,接下来就需要部署CNI了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 $ kubectl cluster-info'kubectl cluster-info dump' .
5、安装CNI 5.1 部署calico CNI的部署我们参考官网的自建K8S部署教程 ,官网主要给出了两种部署方式 ,分别是通过Calico operator和Calico manifests来进行部署和管理calico,operator是通过deployment的方式部署一个calico的operator到集群中,再用其来管理calico的安装升级等生命周期操作。manifests则是将相关都使用yaml的配置文件进行管理,这种方式管理起来相对前者比较麻烦,但是对于高度自定义的K8S集群有一定的优势。
这里我们使用operator的方式进行部署。
首先我们把需要用到的两个部署文件下载到本地。
curl https:// raw.githubusercontent.com/projectcalico/ calico/v3.24.5/m anifests/tigera-operator.yaml -O// raw.githubusercontent.com/projectcalico/ calico/v3.24.5/m anifests/custom-resources.yaml -O
随后我们修改custom-resources.yaml里面的pod ip段信息和划分子网的大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: operator.tigera.io/v1 kind: Installation metadata: name: default spec: calicoNetwork: ipPools: - blockSize: 24 cidr: 10.33 .0 .0 /17 encapsulation: VXLANCrossSubnet natOutgoing: Enabled nodeSelector: all() --- apiVersion: operator.tigera.io/v1 kind: APIServer metadata: name: default spec: {}
最后我们直接部署
kubectl create -f tigera-operator .yamlcreate -f custom-resources.yaml
此时部署完成之后我们应该可以看到所有的pod和node都已经处于正常工作状态。接下来我们进入高级配置阶段
5.2 安装calicoctl 接下来我们就要部署calicoctl 来帮助我们管理calico的相关配置,为了使用 Calico 的许多功能,需要 calicoctl 命令行工具。它用于管理 Calico 策略和配置,以及查看详细的集群状态。
The calicoctl command line tool is required in order to use many of Calico’s features. It is used to manage Calico policies and configuration, as well as view detailed cluster status.
这里我们可以直接使用二进制部署安装
curl -L https://gi thub.com/projectcalico/ calico/releases/ download/v3.24.5/ calicoctl-linux-amd64 -o /usr/ local/bin/ calicoctl/usr/ local/bin/ calicoctl
至于配置也比较简单,因为我们这里使用的是直接连接apiserver的方式,所以直接配置环境变量即可
export CALICO_DATASTORE_TYPE=kubernetesexport CALICO_KUBECONFIG=~/.kube/config
5.3 配置BGP 一般来说,calico的BGP拓扑 可以分为三种配置:
Full-mesh(全网状连接) :启用 BGP 后,Calico 的默认行为是创建内部 BGP (iBGP) 连接的全网状 连接,其中每个节点相互对等。这允许 Calico 在任何 L2 网络上运行,无论是公共云还是私有云,或者是配置 了基于IPIP的overlays网络。Calico 不将 BGP 用于 VXLAN overlays网络。 全网状结构非常适合 100 个或更少节点的中小型部署,但在规模明显更大的情况下,全网状结构的效率会降低,calico建议使用路由反射器(Route reflectors)。
Route reflectors(路由反射器) :要构建大型内部 BGP (iBGP) 集群,可以使用BGP 路由反射器 来减少每个节点上使用的 BGP 对等体的数量。在这个模型中,一些节点充当路由反射器,并被配置为在它们之间建立一个完整的网格。然后将其他节点配置为与这些路由反射器的子集对等(通常为 2 个用于冗余),与全网状相比减少了 BGP 对等连接的总数。
Top of Rack (ToR):在 本地部署 中,我们可以直接让calico和物理网络基础设施建立BGP连接,一般来说这需要先把calico默认自带的Full-mesh配置禁用掉,然后将calico和本地的L3 ToR路由建立连接。当整个自建集群的规模很大的时候(通常仅当每个 L2 域中的节点数大于100时),还可以考虑在每个机架内使用BGP的路由反射器(Route reflectors)。
要深入了解常见的本地部署模型,请参阅Calico over IP Fabrics 。
我们这里只是一个小规模的测试集群(6节点),暂时用不上路由反射器这类复杂的配置,因此我们参考第三种TOR的模式,让node直接和我们测试网络内的L3路由器建立BGP连接即可。
在刚初始化的情况下,我们的calico是还没有创建BGPConfiguration,此时我们需要先手动创建,并且禁用nodeToNodeMesh配置,同时还需要借助calico将集群的ClusterIP和ExternalIP都发布出去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ cat calico-bgp-configuration.yaml apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: logSeverityScreen: Info nodeToNodeMeshEnabled: false asNumber: 64517 serviceClusterIPs: - cidr: 10.33 .128 .0 /18 serviceExternalIPs: - cidr: 10.33 .192 .0 /18 listenPort: 179 bindMode: NodeIP communities: - name: bgp-large-community value: 64517 :300:100 prefixAdvertisements: - cidr: 10.33 .0 .0 /17 communities: - bgp-large-community - 64517 :120
另一个就是需要准备BGPPeer的配置,可以同时配置一个或者多个,下面的示例配置了两个BGPPeer,并且ASN号各不相同。其中keepOriginalNextHop默认是不配置的,这里特别配置为true,确保通过BGP宣发pod IP段路由的时候只宣发对应的node,而不是针对podIP也开启ECMP功能。详细的配置可以参考官方文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ cat calico-bgp-peer.yaml apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: openwrt-peer spec: peerIP: 10.31 .254 .253 keepOriginalNextHop: true asNumber: 64512 --- apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: tiny-unraid-peer spec: peerIP: 10.31 .100 .100 keepOriginalNextHop: true asNumber: 64516
配置完成之后我们直接部署即可,这时候集群默认的node-to-node-mesh就已经被我们禁用,此外还可以看到我们配置的两个BGPPeer已经顺利建立连接并发布路由了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ kubectl create -f calico-bgp-configuration.yaml
6、配置LoadBalancer 目前市面上开源的K8S-LoadBalancer主要就是MetalLB 、OpenELB 和PureLB 这三种,三者的工作原理和使用教程我都写文章分析过,针对目前这种使用场景,我个人认为最合适的是使用PureLB,因为他的组件高度模块化,并且可以自由选择实现ECMP模式的路由协议和软件(MetalLB和OpenELB都是自己通过gobgp实现的BGP协议),能更好的和我们前面的calico BGP模式组合在一起,借助calico自带的BGP配置把LoadBalancer IP发布到集群外。
关于purelb的详细工作原理和部署使用方式可以参考我之前写的这篇文章 ,这里不再赘述。
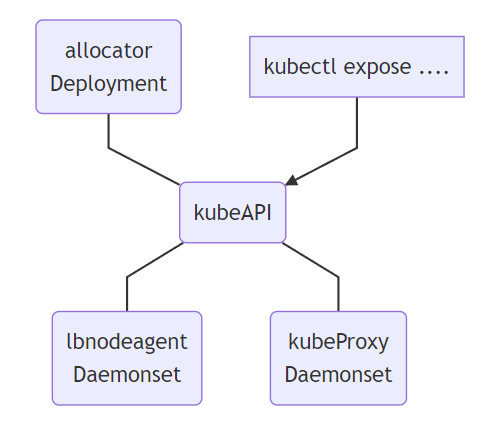
Allocator :用来监听API中的LoadBalancer类型服务,并且负责分配IP。LBnodeagent : 作为daemonset部署到每个可以暴露请求并吸引流量的节点上,并且负责监听服务的状态变化同时负责把VIP添加到本地网卡或者是虚拟网卡KubeProxy :k8s的内置组件,并非是PureLB的一部分,但是PureLB依赖其进行正常工作,当对VIP的请求达到某个具体的节点之后,需要由kube-proxy来负责将其转发到对应的pod
因为我们此前已经配置了calico的BGP模式,并且会由它来负责BGP宣告的相关操作,因此在这里我们直接使用purelb的BGP模式,并且不需要自己再额外部署bird或frr来进行BGP路由发布,同时也不需要LBnodeagent组件来帮助暴露并吸引流量,只需要Allocator帮助我们完成LoadBalancerIP的分配操作即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 cat purelb-ipam.yamllocal :'10.33.192.0/18' '10.33.192.0-10.33.255.254'
到这里我们的PureLB就部署完了,相比完整的ECMP模式要少部署了路由协议软件 和**额外删除了lbnodeagent**,接下来可以开始测试了。
7、部署测试用例 集群部署完成之后我们在k8s集群中部署一个nginx测试一下是否能够正常工作。首先我们创建一个名为nginx-quic的命名空间(namespace),然后在这个命名空间内创建一个名为nginx-quic-deployment的deployment用来部署pod,最后再创建一个service用来暴露服务,这里我们同时使用nodeport和LoadBalancer两种方式来暴露服务,并且其中一个LoadBalancer的服务还要指定LoadBalancerIP方便我们测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 apiVersion: v1 kind: Namespace metadata: name: nginx-quic --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx-quic-deployment namespace: nginx-quic spec: selector: matchLabels: app: nginx-quic replicas: 4 template: metadata: labels: app: nginx-quic spec: containers: - name: nginx-quic image: tinychen777/nginx-quic:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-headless-service namespace: nginx-quic spec: selector: app: nginx-quic clusterIP: None --- apiVersion: v1 kind: Service metadata: name: nginx-quic-service namespace: nginx-quic spec: externalTrafficPolicy: Cluster selector: app: nginx-quic ports: - protocol: TCP port: 8080 targetPort: 80 nodePort: 30088 type: NodePort --- apiVersion: v1 kind: Service metadata: name: nginx-clusterip-service namespace: nginx-quic spec: selector: app: nginx-quic ports: - protocol: TCP port: 8080 targetPort: 80 type: ClusterIP --- apiVersion: v1 kind: Service metadata: annotations: purelb.io/service-group: bgp-ippool name: nginx-lb-service namespace: nginx-quic spec: allocateLoadBalancerNodePorts: true externalTrafficPolicy: Cluster internalTrafficPolicy: Cluster selector: app: nginx-quic ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer loadBalancerIP: 10.33 .192 .80 --- apiVersion: v1 kind: Service metadata: annotations: purelb.io/service-group: bgp-ippool name: nginx-lb2-service namespace: nginx-quic spec: allocateLoadBalancerNodePorts: true externalTrafficPolicy: Cluster internalTrafficPolicy: Cluster selector: app: nginx-quic ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer
部署完成之后我们检查各项服务的状态
$ kubectl get svc -n nginx-quic -o wide-5 d7d9559dd-2 f4kx 1/1 Running 0 2d22h 10.33.26.2 k8s-calico-worker-10 -31 -90 -4 .tinychen.io <none> <none>-5 d7d9559dd-8 gm7s 1/1 Running 0 2d22h 10.33.93.3 k8s-calico-worker-10 -31 -90 -6 .tinychen.io <none> <none>-5 d7d9559dd-jwhth 1/1 Running 0 2d22h 10.33.93.2 k8s-calico-worker-10 -31 -90 -6 .tinychen.io <none> <none>-5 d7d9559dd-qxhqh 1/1 Running 0 2d22h 10.33.12.2 k8s-calico-worker-10 -31 -90 -5 .tinychen.io <none> <none>
随后我们分别在集群内外的机器进行测试,分别访问podIP 、clusterIP和loadbalancerIP。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
最后检测一下路由器端的情况,可以看到对应的podIP、clusterIP和loadbalancerIP段路由
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 B>* 10.33.5.0 /24 [20 /0 ] via 10.31.90.1 , eth0, weight 1 , 2d 19h22m10.33.12.0 /24 [20 /0 ] via 10.31.90.5 , eth0, weight 1 , 2d 19h22m10.33.23.0 /24 [20 /0 ] via 10.31.90.2 , eth0, weight 1 , 2d 19h22m10.33.26.0 /24 [20 /0 ] via 10.31.90.4 , eth0, weight 1 , 2d 19h22m10.33.57.0 /24 [20 /0 ] via 10.31.90.3 , eth0, weight 1 , 2d 19h22m10.33.93.0 /24 [20 /0 ] via 10.31.90.6 , eth0, weight 1 , 2d 19h22m10.33.128.0 /18 [20 /0 ] via 10.31.90.1 , eth0, weight 1 , 00 :00 :20 10.31.90.2 , eth0, weight 1 , 00 :00 :20 10.31.90.3 , eth0, weight 1 , 00 :00 :20 10.31.90.4 , eth0, weight 1 , 00 :00 :20 10.31.90.5 , eth0, weight 1 , 00 :00 :20 10.31.90.6 , eth0, weight 1 , 00 :00 :20 10.33.192.0 /18 [20 /0 ] via 10.31.90.1 , eth0, weight 1 , 2d 19h21m10.31.90.2 , eth0, weight 1 , 2d 19h21m10.31.90.3 , eth0, weight 1 , 2d 19h21m10.31.90.4 , eth0, weight 1 , 2d 19h21m10.31.90.5 , eth0, weight 1 , 2d 19h21m10.31.90.6 , eth0, weight 1 , 2d 19h21m
到这里整个K8S集群就部署完成了。