# 修改前 $ grep server /etc/chrony.conf # Use public servers from the pool.ntp.org project. server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst
# 修改后 $ grep server /etc/chrony.conf # Use public servers from the pool.ntp.org project. server ntp.ntsc.ac.cn iburst
This requirement is only needed if you run cilium-agent natively. If you are using the Cilium container image cilium/cilium, clang+LLVM is included in the container image.
iproute2 is only needed if you run cilium-agent directly on the host machine. iproute2 is included in the cilium/cilium container image.
In order for the eBPF feature to be enabled properly, the following kernel configuration options must be enabled. This is typically the case with distribution kernels. When an option can be built as a module or statically linked, either choice is valid.
FAQ: For Kubernetes, do I need to download cri-containerd-(cni-)<VERSION>-<OS-<ARCH>.tar.gz too?
Answer: No.
As the Kubernetes CRI feature has been already included in containerd-<VERSION>-<OS>-<ARCH>.tar.gz, you do not need to download the cri-containerd-.... archives to use CRI.
The cri-containerd-... archives are deprecated, do not work on old Linux distributions, and will be removed in containerd 2.0.
# Download the cni-plugins-<OS>-<ARCH>-<VERSION>.tgz archive from https://github.com/containernetworking/plugins/releases , verify its sha256sum, and extract it under /opt/cni/bin:
# 查看containerd状态的时候我们可以看到cni相关的报错 # 这是因为我们先安装了cni-plugins但是还没有安装k8s的cni插件 # 属于正常情况 $ systemctl status containerd -l May 12 09:57:31 tiny-kubeproxy-free-master-18-1.k8s.tcinternal containerd[5758]: time="2022-05-12T09:57:31.100285056+08:00" level=error msg="failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni config load failed: no network config found in /etc/cni/net.d: cni plugin not initialized: failed to load cni config"
# 初始化,注意添加参数跳过kube-proxy的安装 $ kubeadm init --config kubeadm-kubeproxy-free.conf --skip-phases=addon/kube-proxy [init] Using Kubernetes version: v1.24.0 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' ...此处略去一堆输出...
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
$ kubectl cluster-info Kubernetes control plane is running at https://10.31.18.1:6443 CoreDNS is running at https://10.31.18.1:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME tiny-kubeproxy-free-master-18-1.k8s.tcinternal NotReady control-plane 2m46s v1.24.0 10.31.18.1 <none> CentOS Linux 7 (Core) 5.17.6-1.el7.elrepo.x86_64 containerd://1.6.4
$ kubeadm join 10.31.18.1:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:7772f5461bdf4dc399618dc226e2d718d35f14b079e904cd68a5b148eaefcbdd [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' W0512 10:34:36.673112 7960 configset.go:78] Warning: No kubeproxy.config.k8s.io/v1alpha1 config is loaded. Continuing without it: configmaps "kube-proxy" is forbidden: User "system:bootstrap:abcdef" cannot get resource "configmaps"in API group ""in the namespace "kube-system" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
$ kubectl get nodes NAME STATUS ROLES AGE VERSION tiny-kubeproxy-free-master-18-1.k8s.tcinternal NotReady control-plane 11m v1.24.0 tiny-kubeproxy-free-worker-18-11.k8s.tcinternal NotReady <none> 5m57s v1.24.0 tiny-kubeproxy-free-worker-18-12.k8s.tcinternal NotReady <none> 65s v1.24.0
$ helm install cilium cilium/cilium --version 1.11.4 --namespace kube-system --set kubeProxyReplacement=strict --set k8sServiceHost=10.31.18.1 --set k8sServicePort=6443 --set ipam.operator.clusterPoolIPv4PodCIDRList=10.18.64.0/18 --set ipam.operator.clusterPoolIPv4MaskSize=24 W0512 11:03:06.636996 8753 warnings.go:70] spec.template.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[1].matchExpressions[0].key: beta.kubernetes.io/os is deprecated since v1.14; use "kubernetes.io/os" instead W0512 11:03:06.637058 8753 warnings.go:70] spec.template.metadata.annotations[scheduler.alpha.kubernetes.io/critical-pod]: non-functional in v1.16+; use the "priorityClassName" field instead NAME: cilium LAST DEPLOYED: Thu May 12 11:03:04 2022 NAMESPACE: kube-system STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: You have successfully installed Cilium with Hubble.
Your release version is 1.11.4.
For any further help, visit https://docs.cilium.io/en/v1.11/gettinghelp
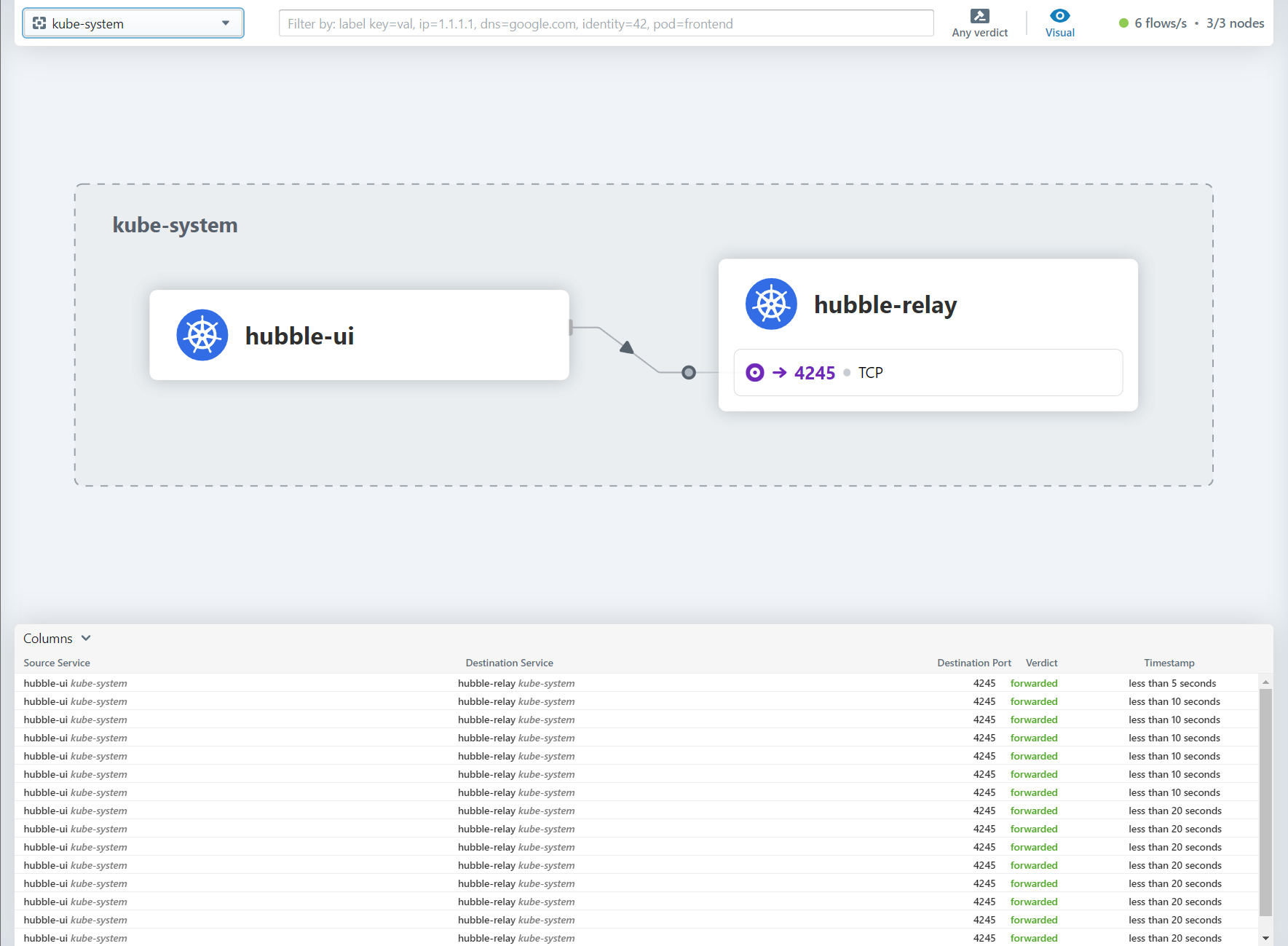
此时我们再查看集群的daemonset和deployment状态:
1 2 3 4 5 6 7 8
# 这时候查看集群的daemonset和deployment状态可以看到cilium相关的服务已经正常 $ kubectl get ds -A NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-system cilium 3 3 3 3 3 <none> 4m57s $ kubectl get deploy -A NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system cilium-operator 2/2 2 2 5m4s kube-system coredns 2/2 2 2 39m
# --verbose参数可以查看详细的状态信息 # cilium-97fn7需要替换为任意一个cilium的pod $ kubectl exec -it -n kube-system cilium-97fn7 -- cilium status --verbose Defaulted container "cilium-agent" out of: cilium-agent, mount-cgroup (init), clean-cilium-state (init) KVStore: Ok Disabled Kubernetes: Ok 1.24 (v1.24.0) [linux/amd64] Kubernetes APIs: ["cilium/v2::CiliumClusterwideNetworkPolicy", "cilium/v2::CiliumEndpoint", "cilium/v2::CiliumNetworkPolicy", "cilium/v2::CiliumNode", "core/v1::Namespace", "core/v1::Node", "core/v1::Pods", "core/v1::Service", "discovery/v1::EndpointSlice", "networking.k8s.io/v1::NetworkPolicy"] KubeProxyReplacement: Strict [eth0 10.31.18.11 (Direct Routing)] Host firewall: Disabled Cilium: Ok 1.11.4 (v1.11.4-9d25463) NodeMonitor: Listening for events on 8 CPUs with 64x4096 of shared memory Cilium health daemon: Ok IPAM: IPv4: 2/254 allocated from 10.18.66.0/24, Allocated addresses: 10.18.66.223 (health) 10.18.66.232 (router) BandwidthManager: Disabled Host Routing: Legacy Masquerading: IPTables [IPv4: Enabled, IPv6: Disabled] Clock Source for BPF: ktime Controller Status: 21/21 healthy Name Last success Last error Count Message bpf-map-sync-cilium_ipcache 3s ago 8m59s ago 0 no error cilium-health-ep 41s ago never 0 no error dns-garbage-collector-job 59s ago never 0 no error endpoint-2503-regeneration-recovery never never 0 no error endpoint-82-regeneration-recovery never never 0 no error endpoint-gc 3m59s ago never 0 no error ipcache-inject-labels 8m49s ago 8m53s ago 0 no error k8s-heartbeat 29s ago never 0 no error mark-k8s-node-as-available 8m41s ago never 0 no error metricsmap-bpf-prom-sync 4s ago never 0 no error resolve-identity-2503 3m41s ago never 0 no error resolve-identity-82 3m42s ago never 0 no error sync-endpoints-and-host-ips 42s ago never 0 no error sync-lb-maps-with-k8s-services 8m42s ago never 0 no error sync-node-with-ciliumnode (tiny-kubeproxy-free-worker-18-11.k8s.tcinternal) 8m53s ago 8m55s ago 0 no error sync-policymap-2503 33s ago never 0 no error sync-policymap-82 30s ago never 0 no error sync-to-k8s-ciliumendpoint (2503) 11s ago never 0 no error sync-to-k8s-ciliumendpoint (82) 2s ago never 0 no error template-dir-watcher never never 0 no error update-k8s-node-annotations 8m53s ago never 0 no error Proxy Status: OK, ip 10.18.66.232, 0 redirects active on ports 10000-20000 Hubble: Ok Current/Max Flows: 422/4095 (10.31%), Flows/s: 0.75 Metrics: Disabled KubeProxyReplacement Details: Status: Strict Socket LB Protocols: TCP, UDP Devices: eth0 10.31.18.11 (Direct Routing) Mode: SNAT Backend Selection: Random Session Affinity: Enabled Graceful Termination: Enabled XDP Acceleration: Disabled Services: - ClusterIP: Enabled - NodePort: Enabled (Range: 30000-32767) - LoadBalancer: Enabled - externalIPs: Enabled - HostPort: Enabled BPF Maps: dynamic sizing: on (ratio: 0.002500) Name Size Non-TCP connection tracking 65536 TCP connection tracking 131072 Endpoint policy 65535 Events 8 IP cache 512000 IP masquerading agent 16384 IPv4 fragmentation 8192 IPv4 service 65536 IPv6 service 65536 IPv4 service backend 65536 IPv6 service backend 65536 IPv4 service reverse NAT 65536 IPv6 service reverse NAT 65536 Metrics 1024 NAT 131072 Neighbor table 131072 Global policy 16384 Per endpoint policy 65536 Session affinity 65536 Signal 8 Sockmap 65535 Sock reverse NAT 65536 Tunnel 65536 Encryption: Disabled Cluster health: 3/3 reachable (2022-05-12T03:12:22Z) Name IP Node Endpoints tiny-kubeproxy-free-worker-18-11.k8s.tcinternal (localhost) 10.31.18.11 reachable reachable tiny-kubeproxy-free-master-18-1.k8s.tcinternal 10.31.18.1 reachable reachable tiny-kubeproxy-free-worker-18-12.k8s.tcinternal 10.31.18.12 reachable reachable
apiVersion:v1 kind:Service metadata: name:nginx-quic-service namespace:nginx-quic spec: externalTrafficPolicy:Cluster selector: app:nginx-quic ports: -protocol:TCP port:8080# match for service access port targetPort:80# match for pod access port nodePort:30088# match for external access port type:NodePort
# 直接部署 $ kubectl apply -f nginx-quic.yaml namespace/nginx-quic created deployment.apps/nginx-quic-deployment created service/nginx-quic-service created
# 查看deployment的运行状态 $ kubectl get deployment -o wide -n nginx-quic NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx-quic-deployment 4/4 4 4 2m49s nginx-quic tinychen777/nginx-quic:latest app=nginx-quic
# 查看service的运行状态 $ kubectl get service -o wide -n nginx-quic NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR nginx-quic-service NodePort 10.18.54.119 <none> 8080:30088/TCP 3m app=nginx-quic