使用python导出华为网络设备中的配置为excel文件
本文最后更新于:August 16, 2019 pm
项目github地址:https://github.com/tiny777/ServersManagementTools
0、概述
这个脚本需要实现的功能很简单,就是自动ssh登录到网络设备上,查询相应的白名单,然后将结果导出成excel表格,具体的操作命令如下,对应的设备是华为的AC6605。
1 | |
- 由于这里使用的是
netmiko库,所以除了华为的网络设备,思科的设备也能支持,只需要在代码文件中稍作修改即可。 - 相应的命令也可以进行修改成其他的系列命令
1、软件版本
eNSP的BUG非常多,这里搭建拓扑来进行测试使用的软件版本是
eNSP 1.2.00.500 V100R002C00VirtualBox Graphical User Interface Version 5.1.26r117224(Qt5.6.2)WinPcap_4_1_3- Wireshark没有用到,版本应该无所谓
- 操作系统是
win10 pro,Microsoft Windows Version 1903(OS Build 18362.239)
2、配置eNSP桥接真机
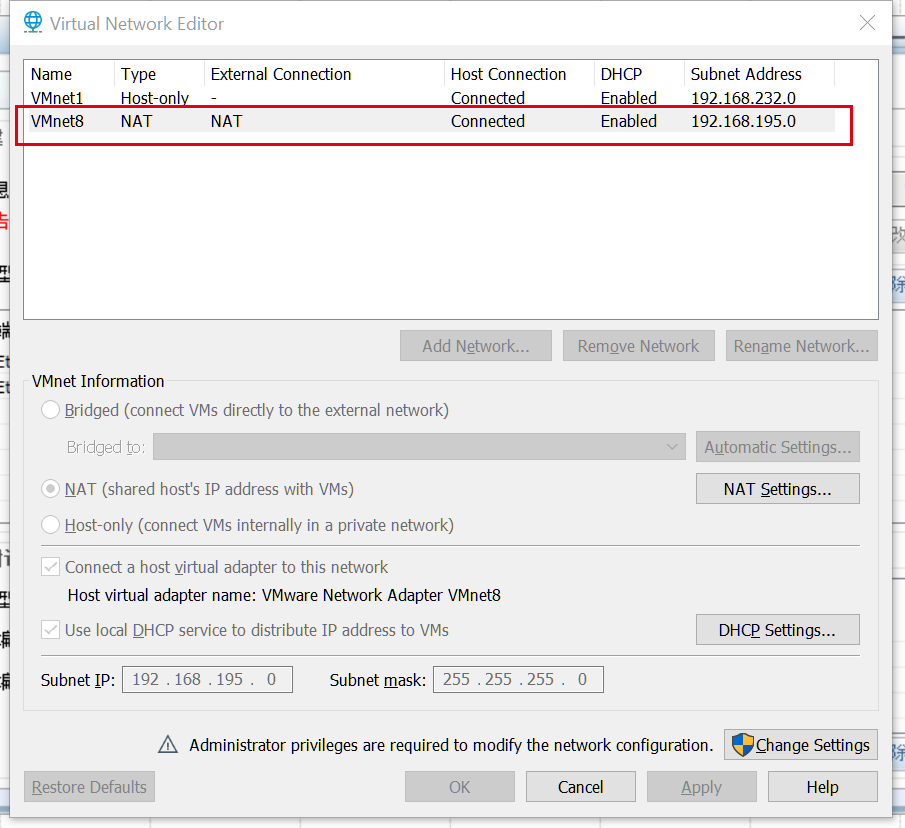
这里使用的是AC6605,对真机进行桥接,使用的桥接网卡是VMware WorkStation 15.1 的VMnet8网卡,即NAT模式的网卡,不是eNSP上面的192.168.56.1的那个网卡(这个老是有问题,各种ping不同)。
接下来的eNSP内的桥接配置就十分简单了,添加一个UDP端口,然后添加一个网卡,再添加端口映射,就可以了。可以参考下面的这张图。

接着我们拖入一个设备,我这里使用的是华为的AC6605。
给它配置一个IP地址然后测试一下。
1 | |
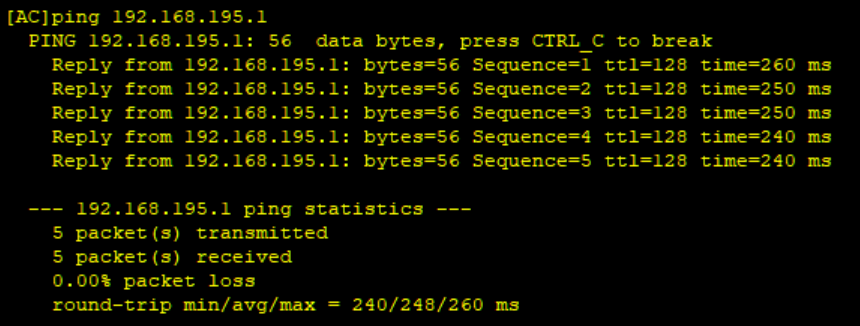
然后我们ping一下真机的网卡,能通就说明桥接成功了。
3、配置SSH服务
首先进行系统视图,然后创建rsa key,全部选择默认,接着启动stelnet服务。
1 | |
接着配置用来远程的终端
1 | |
然后创建用户并设置密码。然后启动ssh服务。
1 | |
最后回到系统视图下,设置ssh用户的登录方式为密码登录。
1 | |
4、保存配置
上面的所有配置如果不保存,当前的终端退出就会失效,所以要记得保存配置,方法是退到最开始的登录视图输入save就能保存了。
5、def sshLogin
这里使用netmiko来对网络设备进行ssh登录,考虑到获取到的结果是包含了命令执行过程中的所有套接字,因此得到结果之后,先将其全部写入一个debug.log文件中保存记录,再将该次的操作结果写入cache文件用于下一步处理。
6、def sort_to_csv
对于输出的结果进行筛选处理,我们需要用到re库的正则表达式,以及split(),因为大多数的输出结果是以空格来分列的,因此使用split()来处理这些字符是最好不过的了。
最后导出成csv文件而不是直接导出excel的xlsx文件则是因为csv相比xlsx更容易读取处理,转成其他格式也更加方便。
7、def csv_to_xlsx_pd
这里就是使用pandas库来将上一步生成的csv转为xlsx文件了,非常的简单,需要的注意的就是添加的行名和列名参数。