本文最后更新于:August 10, 2021 pm
本文主要介绍基于CentOS7.9系统部署DPVS的FullNAT模式的各种部署方式和配置管理,包括IPv4-IPv4、bonding、IPv6-IPv6、IPv6-IPv4(NAT64)和keepalived模式这五种方案。
以下的配置全部基于双臂模式,并且RS机器上面已经安装了DPVS相应的toa模块。我们先从单个网卡的IPv4简单配置开始,接着再做bonding配置,然后再进行IPv6简单配置,NAT64配置以及最后使用keepalived配置主备模式。
本文中安装的DPVS版本为1.8-10,dpdk版本为18.11.2,详细安装过程已在之前的文章DPVS-FullNAT模式部署篇 - TinyChen’s Studio 中叙述过,这里不做赘述。
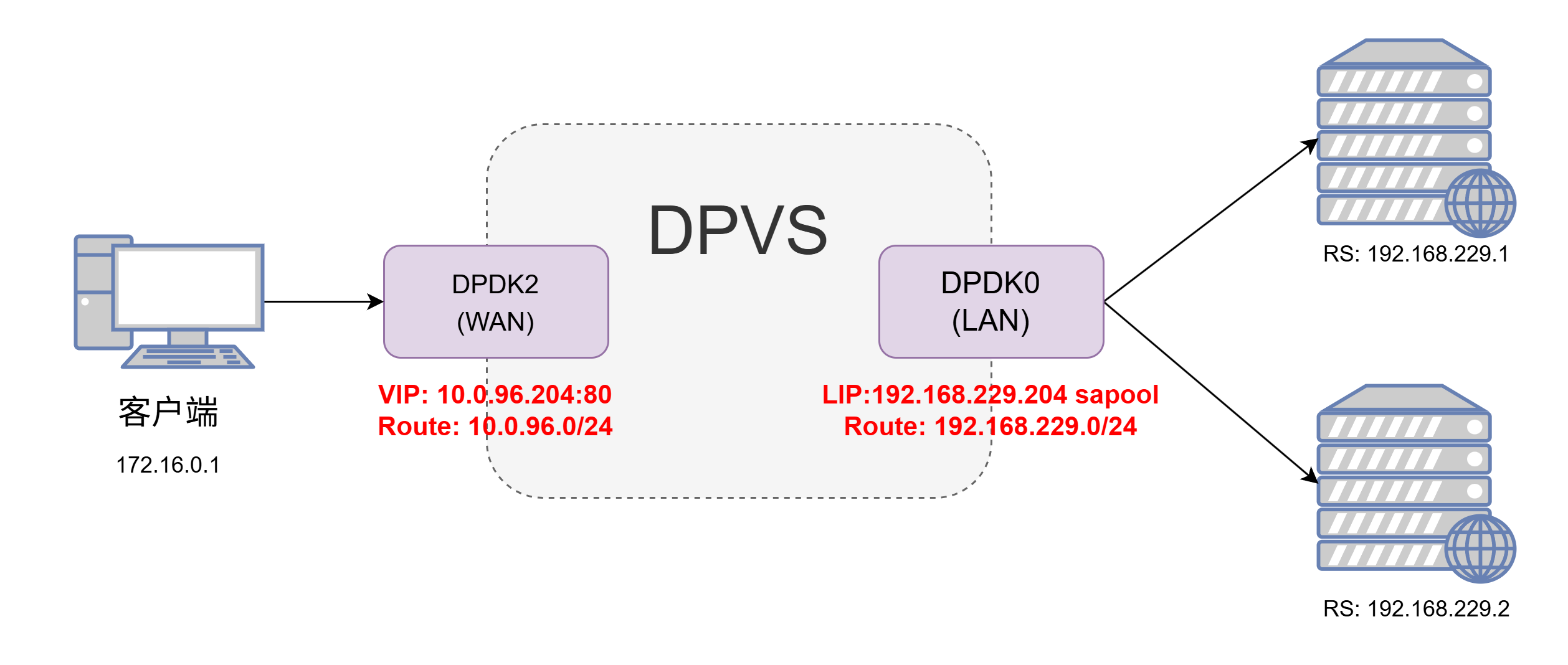
1、IPv4简单配置 1.1 架构图 首先是最简单的配置方式,直接使用ipvsadm的命令行操作来实现一个IPv4网络的FullNat模式,架构图如下:
这里我们使用dpdk2网卡作为wan口,dpdk0网卡作为lan口
1.2 配置过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 link metric 0 proto autolink metric 0 proto autoln
然后我们在RS上面启动一个nginx,设置返回IP和端口号,然后直接对VIP使用ping和curl命令进行测试:
$ ping -c4 10.0.96.204
1.3 小结 该模式非常的简单,可以快速配置检验自己机器上的DPVS能否正常工作,不过由于是单点,往往较少使用。
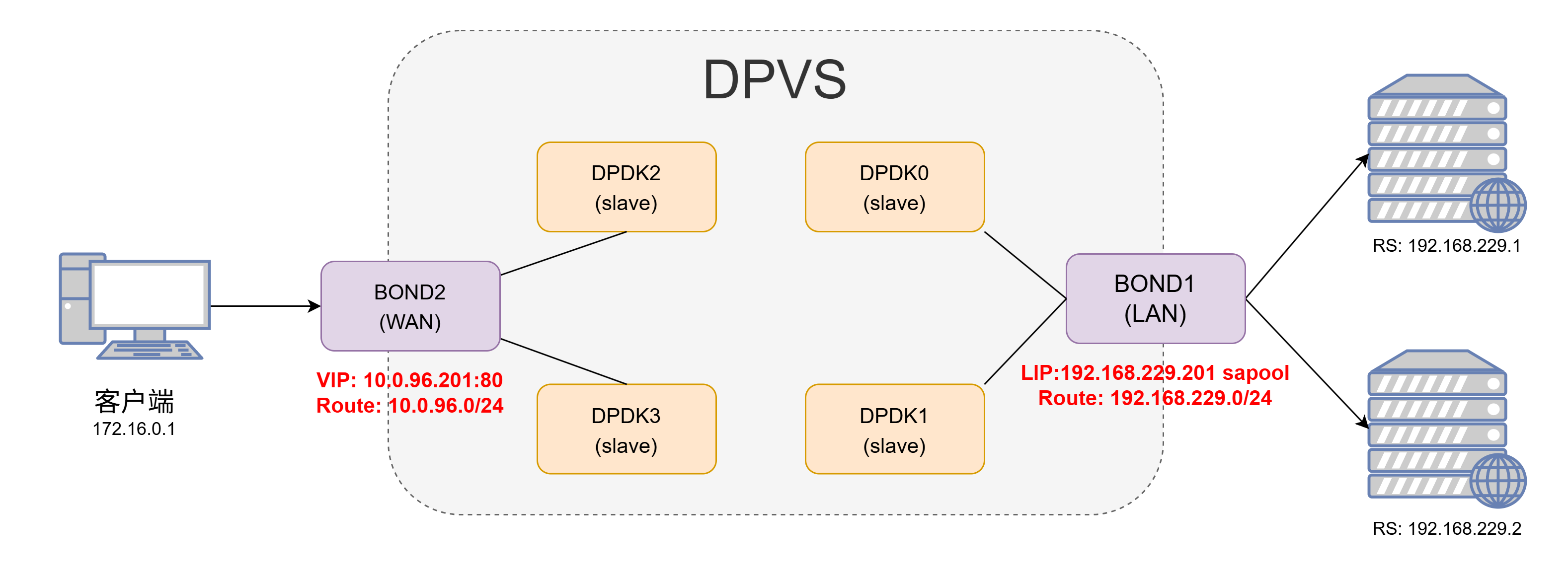
2、bonding配置 目前DPVS支持配置bonding4和bonding0,两者的配置基本相同,配置方式可以参考dpvs/conf/dpvs.conf.single-bond.sample这个文件。
配置bonding模式的时候,不需要对slave网卡(如dpdk0等)指定kni_name这个参数,而是要在bonding中指定对应的kni_name,同时还要注意primary参数指定的网卡的MAC地址一般就是bonding网卡的MAC地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 ! netif configpktpool_size 1048575 256 rx {max_burst_size 32 16 1024 max_burst_size 32 16 1024 mode perfect64k 1500 rx {max_burst_size 32 16 1024 max_burst_size 32 16 1024 mode perfect64k 1500 rx {max_burst_size 32 16 1024 max_burst_size 32 16 1024 mode perfect64k 1500 rx {max_burst_size 32 16 1024 max_burst_size 32 16 1024 mode perfect64k 1500 mode 4 mode 4
随后在配置每个worker-cpu的时候要注意port要选择对应的bond网卡
<init> worker cpu1 {type slave1 rx_queue_ids 0 0 rx_queue_ids 0 0
DPVS的bonding配置和在Linux中直接操作一样。bonding配置成功后只需要对生成的bonding网卡操作即可,使用dpip命令可以查看对应网卡的工作状态:如下面的网卡就工作在全双工、20000 Mbps速率的模式下,MTU为1500,并且在DPVS中配置了16个收发队列。
$ dpip link show
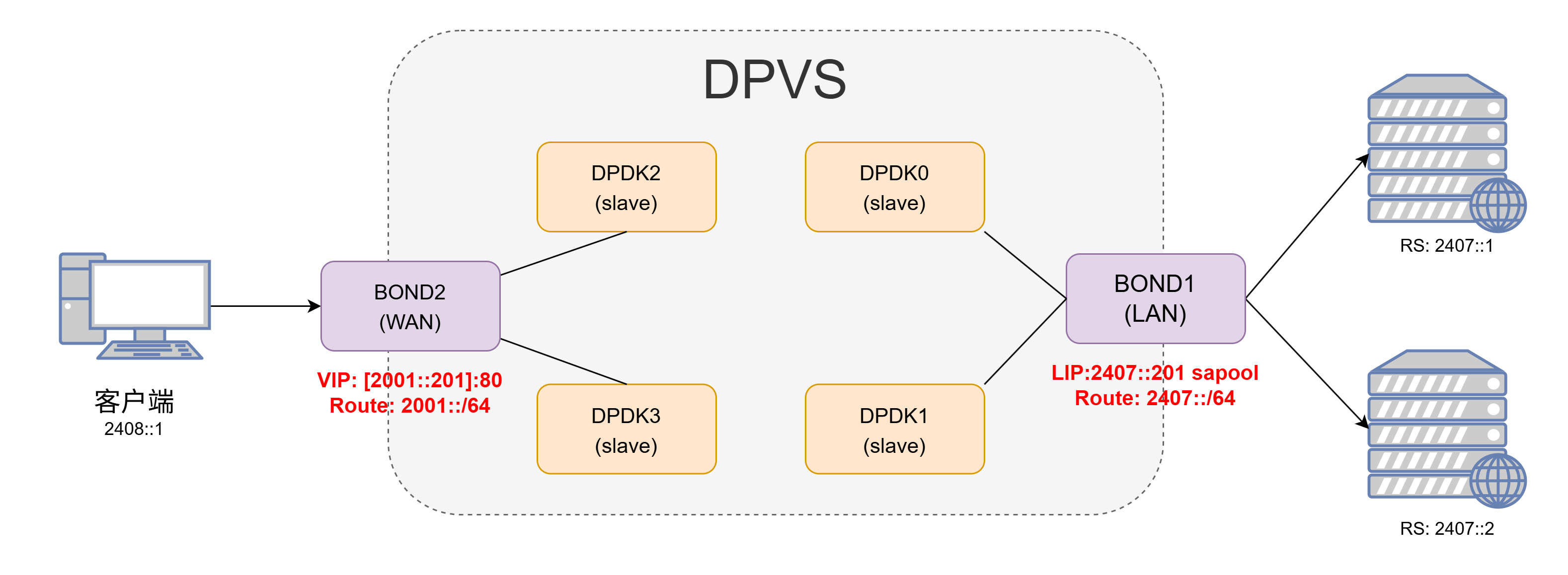
3、IPv6简单配置 3.1 DPVS配置过程 IPv6的简单配置方法和IPv4一样,只是把对应的IPv4地址换成了IPv6地址,同时还需要额外注意一下IPv6地址指定端口的时候需要使用[]将IP地址括起来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 link link
3.2 效果检验 测试效果,确认RS上面的nginx能够正常返回用户端的真实IP和端口,则表明配置正常。
$ curl -6 "http://\[2001::201\]"
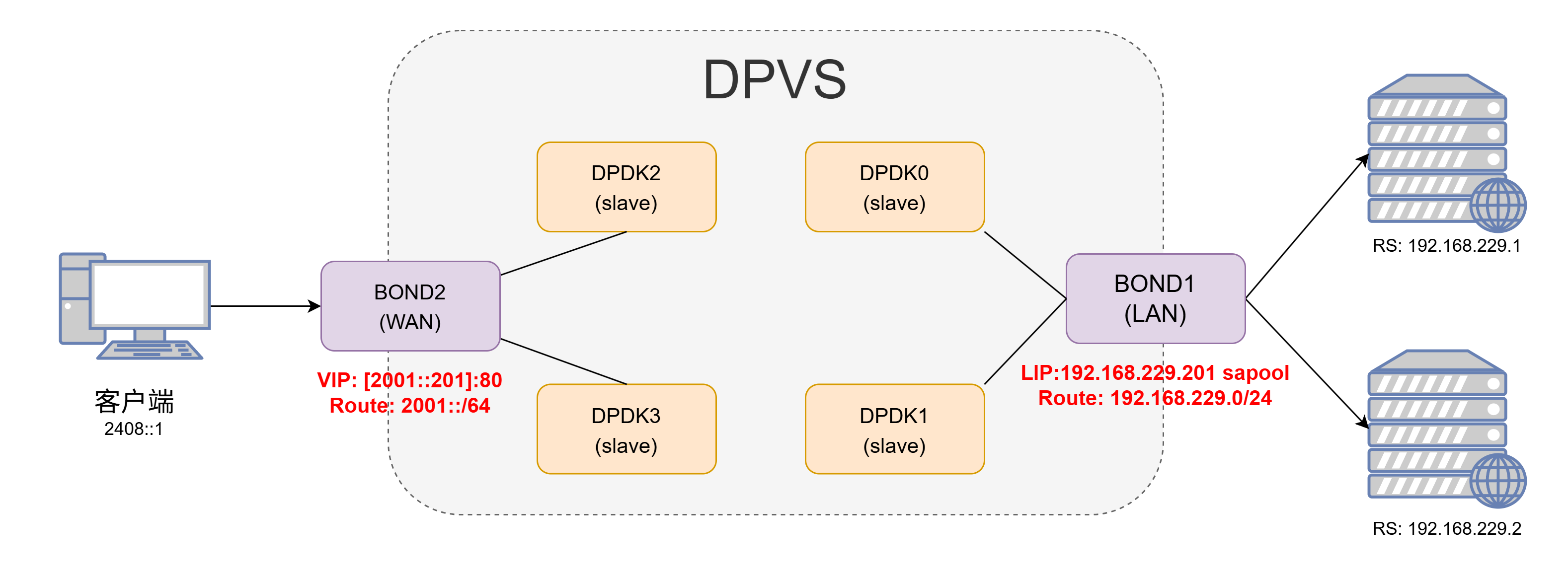
4、NAT64配置 4.1 DPVS配置过程 架构图上和之前的两个并没太大的不同,只是IP略有差异
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 link metric 0 proto autolink ln
测试效果
$ curl -6 "http://\[2001::201\]"
从上面的测试结果来看,即使是安装了TOA模块,也无法获取NAT64模式下客户端的源IP地址,所有的客户端IP和端口都会变成LIP转发过来的时候的IP和端口。如果是对源IP没需求的话可以忽略这个问题,如果有需求的话则需要更改RS上面的客户端程序,下面我们以nginx为例。
4.2 NGINX支持NAT64 dpvs还为nginx提供了一个nat64的toa模块,当VIP为ipv6而RS为ipv4的时候,可以使用这个模块在nginx中获取用户真实的ipv6地址,需要我们在源码编译安装nginx之前先打上这个补丁。
从官方的文件名我们可以看出应该是基于1.14.0版本制作的patch,首先我们使用旧版的1.14.0版本能够正常打上补丁,后续的编译安装也能正常进行
$ pwd ls cp /home/dpvs/kmod/toa/example_nat64/nginx/nginx-1.14.0-nat64-toa.patch ./
使用最新的nginx-1.21.1版本的时候会有报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ cp /home/dpvs/kmod/toa/example_nat64/nginx/nginx-1.14.0-nat64-toa.patch ./pwd ls
仔细查看patch文件内容可以发现出现错误是因为1.21.1版本中对应部分移除了几行代码导致patch无法匹配,我们手动将那一行代码加上去
随后就能正常编译安装了,完成之后我们可以在日志中加入$toa_remote_addr和$toa_remote_port这两个变量来获取NAT64模式下的客户端真实IP。
4.3 效果检验 再次测试发现能够显示真正的客户端源IP地址和端口号。
$ curl -6 "http://\[2001::201\]"
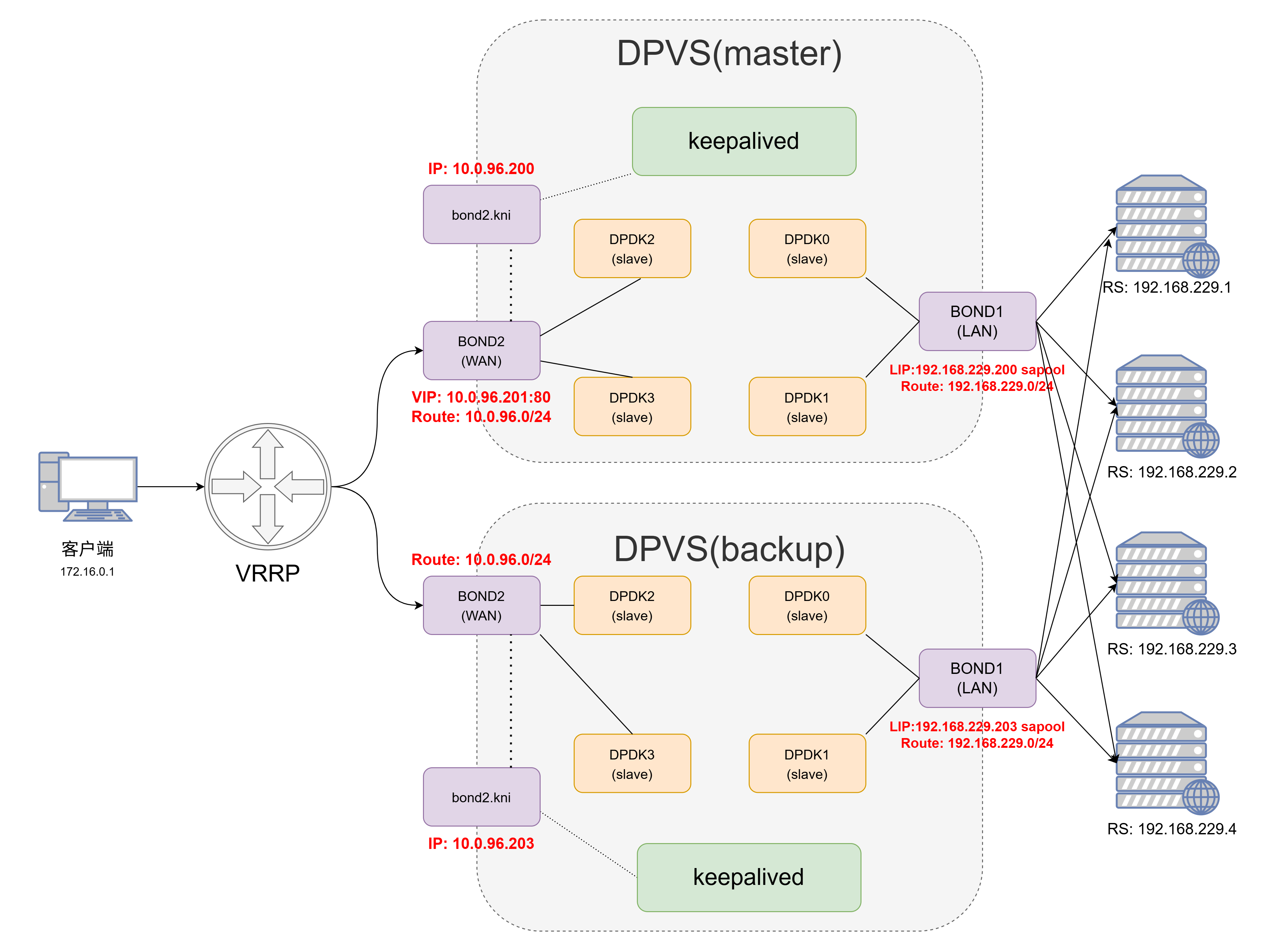
5、keepalived配置 5.1 架构图 使用keepalived配置有两大好处:
VIP、LIP、RS等配置参数可以固化在keepalived的配置文件中,无需每次都使用命令或脚本手动操作
keepalived可以使用VRRP协议配置主备模式(master-backup),避免了单点问题
官方的keepalived配置网络拓扑使用的是单臂模式,这里我们修改为双臂模式;同时需要注意DPVS使用的keepalived是修改过的版本,和原生版本的keepalived在配置语法和参数上稍有不同 。
和前面提到的一样,keepalived也支持IPv4-IPv4模式、IPv6-IPv6模式和NAT64模式(IPv6-IPv4)这三种模式,三者的不同只是在于路由的不同和keepalived的配置文件略有差异。
5.2 配置kni网卡 keepalived的配置需要在正常的Linux网络栈(非DPVS实现的简单用户态网络栈)中有一个能进行正常网络通信的kni网卡。kni网卡的配置和普通网卡的配置是完全一样的,只需要将配置文件中的DEVICE改为对应的kni网卡即可。
kni网卡的存在依赖于dpvs进程的存在,如果dpvs进程重启了,那么kni网卡不会跟着重启,而是处于DOWN状态直至我们手动将其启用(ifup)
$ cat /etc/sysconfig/network-scripts/ifcfg-bond2.kniyes link /ether a0:36:9f:f0:e4:c0 brd ff:ff:ff:ff:ff:fflink
前面我们的dpvs.conf配置文件中会对每个dpdk网卡或者是bond网卡配置一个kni网卡(一般命名为dpdk0.kni或bond0.kni等),在前面的简单配置步骤中我们都是直接把VIP加到DPDK的网卡上,但是这样无法实现VIP的主备切换,因此这里我们需要将VIP交由keepalived程序控制。
5.3 配置路由 keepalived模式下,对于双臂网络模式的FullNAT,我们需要加的路由一般来说可以直观地分为三大部分:VIP网段的路由,RS/LIP网段的路由,默认路由 。
5.4 配置keepalived 首先我们使用systemctl将keepalived管理起来,首先编写一个unit文件,配置中的路径要替换成DPVS定制版的keepalived二进制文件以及keepalived配置文件的路径(建议使用绝对路径)
$ cat /usr/lib/systemd/system/keepalived.service$MAINPID
随后我们修改keepalived的日志输出到指定的文件中方便我们定位问题
最后我们重启相关的rsyslog日志服务和keepalived
$ systemctl daemon-reloadenable rsyslog.service
5.5 keepalived.conf 注意即使RS相同,NAT64模式和普通的IPv4模式也不能够在同一个vrrp_instance中同时定义IPv4地址和IPv6地址,因为两者使用的VRRP协议版本不同(VRRP和VRRP6)
以下以NAT64和IPv4网络两种配置为例,截取部分重点配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 ! Configuration File for keepalivedrouter_id DPVS_TESTbond1 state MASTER201 100 1 auth_type PASSvrrp_instance VI_2 {state MASTER202 100 1 auth_type PASSvirtual_server_group 10.0.96.201 -80 {virtual_server group 10.0.96.201 -80 {delay_loop 3 192.168.229.1 80 {weight 100 nb_sock_retry 2 3 80 192.168.229.2 80 {weight 100 nb_sock_retry 2 3 80 10.0.96.201 -80 -6 {virtual_server group 10.0.96.201 -80 -6 {delay_loop 3 192.168.229.1 80 {weight 100 nb_sock_retry 2 3 80 192.168.229.2 80 {weight 100 nb_sock_retry 2 3 80
keepalived启动之后,我们就可以使用dpip命令查看到各个定义的VIP,ipvsadm命令中应该可以看到各组RS状态正常
但是需要确保在keepalived运行过程中dpvs必须处于正常运行状态,并且配置文件中interface参数指定的kni网卡处于正常运行状态
每个网卡和网段的相关路由还是需要自己手动添加(IPv4、IPv6)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 ln "http://\[2001::202\]"
最后需要提醒的是,如果使用了NAT64模式,那么nginx是没办法直接获取真实的源端IP的,需要对XFF头进行设置,例如:
proxy_set_header X-Forwarded-For "$real_remote_addr ,$proxy_add_x_forwarded_for " ;map $toa_remote_addr $real_remote_addr {default $toa_remote_addr ;map $toa_remote_port $real_remote_port {default $toa_remote_port ;
6、总结 以上的多种配置中,基本上能在生产环境使用的最好就是keepalived的主备模式 ,此外还有一个需要交换机支持ECMP的多主模式这里因为条件有限暂时没有测试到,后面有条件了再补上。
至于NAT64模式和IPv6-IPv6模式的选择,如果RS是nginx,那么两种模式的区别在于是在nginx上做兼容还是在RS上面配置IPv6网络,具体看实际的网络条件和运维管理工具来判断;如果RS是其他的第三方程序,不想对源代码进行太多的侵入变更,最好就是直接使用IPv6-IPv6模式。